So this next one is an interesting one!
This will only impact you if you are configuring an IP address for syslog.global.logHost via the vRLI vSphere Integraion with host auto configuration + running vRops with the vRLI integration + the vROPS NSX Management Pack with Enable Log Insight integration if configured set to true
Component versions. vRops Version 6.6.1.7243378 Build 7243378 vRops vRLI Solution 6.0.7243380 vROPS NSX Solution 3.5.1.5042743 vRLI Version 4.5.1-6858700
Recently the vRLI cluster I manage went from about ~66million to ~108million records per hour…I started investigating further and discovered that not only did I have the vRLI IP in syslog.global.logHost (expected) but now I also had the vRLI instances FQDN in syslog.global.logHost (what??).
At first I thought this was a bug with the vSphere Integration auto configuration in vRLI, I assumed it was pushing out both 192.168.16.122 and the FQDN… but when I dug deeper I noticed that the account updating the esx hosts syslog.global.logHost with the vRLI FQDN was actually the service account from vRops!

I checked my home lab and to my amazement… I had the same issue… (see below)

hmmm why is vRops pushing out the FQDN when the IP is specified in the vROPS vRLI Solution???
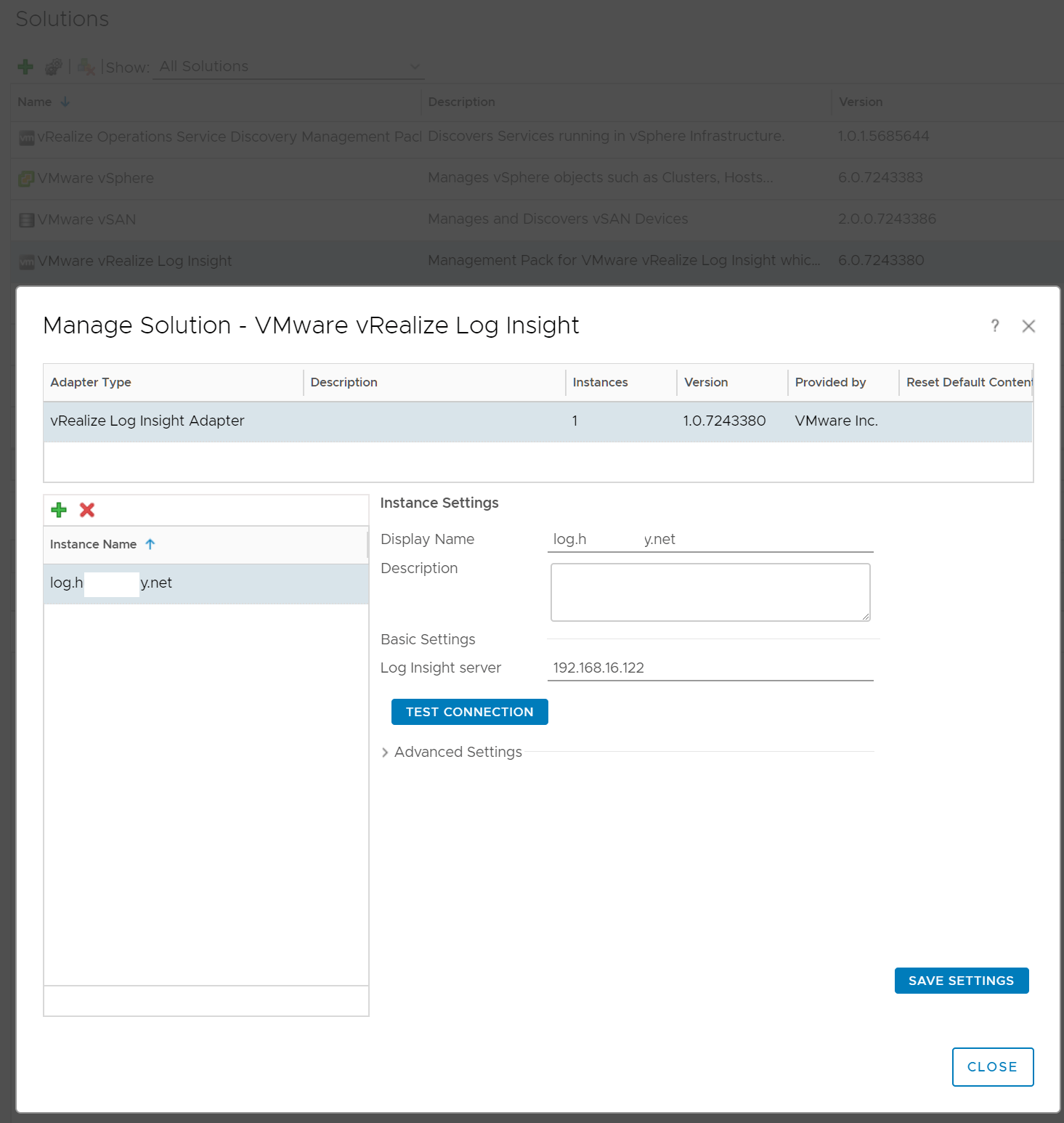
So I suspect that the they recently made vRops perform a reverse lookup on the IP address of the Log Insight server specified in the vRLI Solution to make the integration more seamless… I guess they wanted to get rid of that nasty certificate error from the screen below 🙂

but in the process I think they created a bug for users taking advantage of the vROPS NSX Management Pack setting Enable Log Insight integration if configured

It appears that the management pack is now pushing out the FQDN instead of the IP specified! as you can imagine this duplicates the logs / volumes being sent to vRLI and rolls important logs much faster than originally planned!
Hope this was helpful!
vMan
Recent Comments